
How to move AI Engineering from Current State to Target State
Current State
Traditional software engineering relies on deterministic code execution. Outputs are entirely predictable based on inputs and state. While you excel at building robust, scalable systems using established languages and frameworks, the integration of non-deterministic Large Language Models (LLMs) introduces entirely new paradigms, abstractions, and challenges into the software development lifecycle.
Target State
The goal is to deeply understand the mechanics of integrating intelligence into existing systems. This means designing fault-tolerant architectures that orchestrate LLMs alongside deterministic code, managing the state and memory of multi-turn “agentic” interactions, safely executing tool calls generated by models securely, and deploying specialized observability tooling to evaluate and monitor performance (LLMOps).
Gap Analysis
As an experienced engineer, you don’t need to learn how to write a Python script or hit a REST API. The gap lies in understanding the interaction patterns and limitations of LLMs. You must master how to constrain non-deterministic outputs into predictable structures, how to augment prompts with dynamic context (RAG) at low latency, and design loop-based architectures (Agents) that reason, plan, and execute actions autonomously.
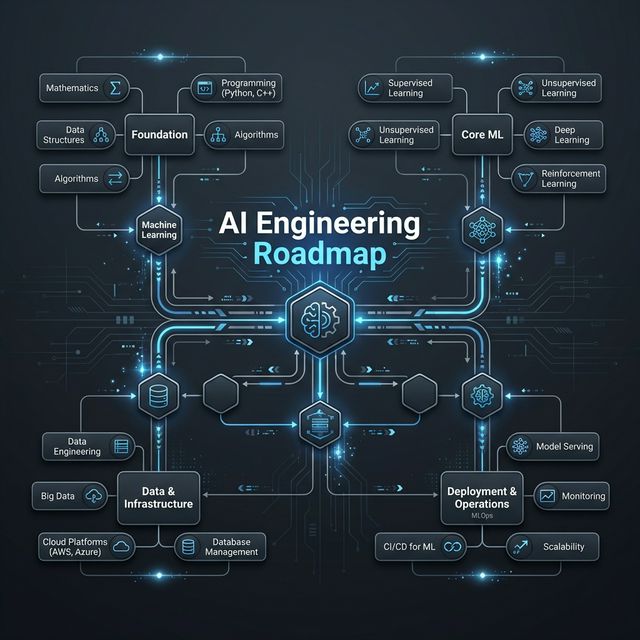
The AI Engineering Roadmap
Agentic AI requires a shift in architectural thinking. Here is a staged roadmap to bridge the gap from traditional engineering to production-ready AI engineering.
Click on each phase to dive into the technical details and implementation patterns.
Phase 1: Advanced Prompting & Constraint Engineering
Focus: Moving beyond basic chat to programmatic, structured model interactions.
Real-World Examples:
- Customer Support Bot: GitHub’s Copilot Chat uses system prompts to constrain responses to code-related queries, refusing off-topic requests
- Data Extraction: Stripe’s API documentation parser uses few-shot examples to extract structured payment flow descriptions from unstructured docs
- Code Generation: Anthropic’s Claude Code uses Chain of Thought reasoning to break down complex feature requests into implementable steps
- Translating system requirements into system prompts and few-shot examples
- Context window management and token optimization
- Structured Output Parsing (Enforcing JSON mode schemas and function calling parameters)
- Reasoning Patterns: Chain of Thought (CoT), ReAct (Reasoning and Acting), Tree of Thoughts
Phase 2: Information Retrieval & Context Augmentation (RAG)
Focus: Supplying dynamic, proprietary data to the LLM at inference time.
Real-World Examples:
- Enterprise Knowledge Base: Notion’s AI assistant retrieves relevant company documents and Slack conversations to answer employee questions about internal processes
- E-commerce Product Search: Shopify’s AI-powered product search uses semantic search to find items based on natural language descriptions (“something comfortable for working from home”)
- **Legal Document Analysis: Ironclad’s contract analysis tool retrieves relevant clause templates and legal precedents to assist with contract review
- Vector Databases and Embedding Models (e.g., Pinecone, pgvector)
- Indexing strategies: Document parsing, chunking algorithms, and metadata filtering
- Retrieval algorithms: Semantic search, Keyword extraction, Hybrid search, and Reranking
- Measuring retrieval quality (Recall@K, MRR)
Phase 3: Model Selection & Integration Mechanics
Focus: Handling the engineering challenges of LLM APIs.
Real-World Examples:
- Content Moderation: Reddit’s content filtering system uses smaller, faster models for initial screening, falling back to larger models only for ambiguous cases
- Real-time Translation: Zoom’s live transcription switches between models based on network conditions and content complexity to maintain low latency
- Code Completion: Tabnine uses local quantized models for basic completions (instant response) and cloud models for complex suggestions (higher quality)
- Trade-offs: Latency vs. Cost vs. Quality (Proprietary APIs vs. running local quantized models)
- Resiliency: Handling rate limits, exponential backoffs, and fallback models
- Performance: Implementing streaming responses (Server-Sent Events) for UX
- Security: API authentication, data privacy, and prompt injection mitigation
Phase 4: Tool Execution & The Model Context Protocol (MCP)
Focus: Giving the model “hands” to mutate state or fetch real-time data securely.
Real-World Examples:
- Database Querying: Microsoft’s Copilot for Business Central generates and executes SQL queries against company databases, with sandboxed execution environments
- API Integration: Zapier’s AI assistant creates and executes API calls between different services (Slack → Google Sheets → Email) based on natural language requests
- File Operations: Claude’s code analysis tool can read, write, and execute files in a controlled environment to perform refactoring tasks
- Defining functions and robust JSON schemas for the model to use
- Model Context Protocol (MCP): Standardizing how tools are presented to the model
- Execution Sandboxing: Safely running code or SQL queries generated by the LLM
- Handling tool execution errors and feeding them back to the model
Phase 5: Orchestration Frameworks & State Management
Focus: Building complex, multi-turn, and multi-agent systems.
Real-World Examples:
- Customer Service Escalation: Bank of America’s Erica uses state management to track conversation context across multiple sessions, escalating to human agents when necessary
- Code Review Pipeline: GitHub’s Copilot Enterprise orchestrates multiple agents: one for code analysis, another for security scanning, and a third for suggesting improvements
- Travel Planning: Expedia’s AI trip planner coordinates multiple specialized agents (flights, hotels, activities) with human approval gates for bookings
- Abstraction evaluation: Building custom deterministic loops vs. Frameworks (LangChain, LlamaIndex, AutoGen)
- State Management: Managing agent memory (short-term vs. long-term) and conversation history over long-running DAGs (LangGraph)
- Multi-Agent Systems: Routing, delegation, and consensus patterns
- Human-in-the-loop (HITL) approval gates
Phase 6: AI-Specific Observability & Evaluation (LLMOps)
Focus: What it takes to run these systems reliably in production.
Real-World Examples:
- Content Quality Monitoring: The New York Times’ AI article summarizer uses LangSmith to track output quality, flagging summaries that deviate from house style or contain factual errors
- Cost Optimization: Duolingo’s AI language practice system monitors token usage and response latency, automatically switching between models to maintain budget constraints
- Safety & Compliance: OpenAI’s enterprise deployments use continuous red-teaming and drift detection to ensure AI assistants remain within policy boundaries
- Tracing LLM execution paths, latency, and token costs using tools like LangSmith or Phoenix
- Evaluation Frameworks: Using LLM-as-a-judge to grade output quality, toxicity, and adherence to instructions
- Prompt versioning and prompt testing (A/B testing prompts)
- Red-teaming and continuous monitoring for drift or hallucinations